What is Retrospective Survey Harmonization?
Joining data from several, differently coded SPSS files.
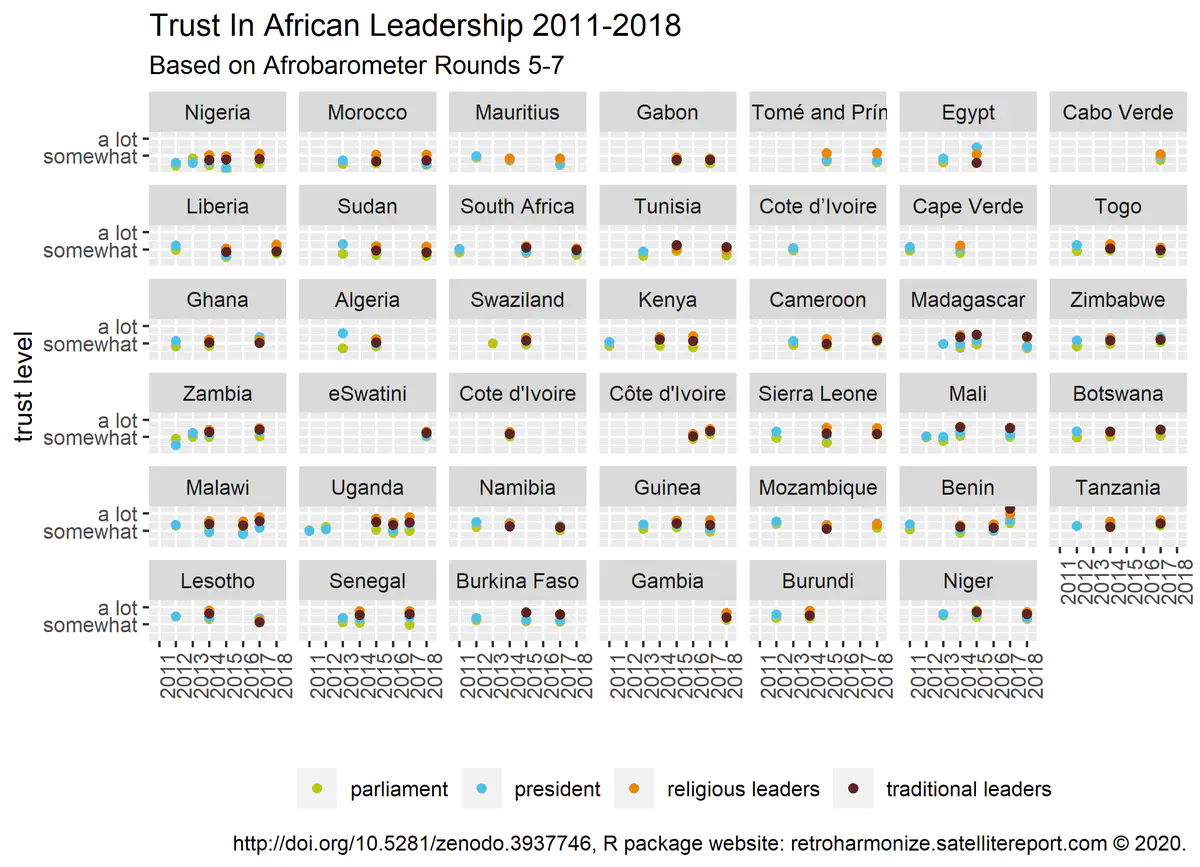 Harmonized survey data example from Afrobarometer (see tutorial
Harmonized survey data example from Afrobarometer (see tutorialReproducible ex post harmonization of survey microdata
Retrospective survey harmonization allows the comparison of opinion poll data conducted in different countries or time. In this example we are working with data from surveys that were ex ante harmonized to a certain degree – in our tutorials we are choosing questions that were asked in the same way in many natural languages. For example, you can compare what percentage of the European people in various countries, provinces and regions thought climate change was a serious world problem back in 2013, 2015, 2017 and 2019.
We developed the retroharmonize R package to help this process. We have tested the package with about 80 Eurobarometer, 5 Afrobarometer survey files extensively, and a bit with Arabbarometer files. This allows the comparison of various survey answers in about 70 countries. This policy-oriented survey programs were designed to be harmonized to a certain degree, but their ex post harmonization is still necessary, challenging and errorprone. Retrospective harmonization includes harmonization of the different coding used for questions and answer options, post-stratification weights, and using different file formats.
Eurobarometer, Afrobaromer, Arab Barometer and Latinobarómetro make survey files that are harmonized across countries available for research with various terms. Our retroharmonize is not affiliated with them, and to run our examples, you must visit their websites, carefully read their terms, agree to them, and download their data yourself. What we add as a value is that we help to connect their files across time (from different years) or across these programs.
The survey programs mentioned above publish their data in the proprietary SPSS format. This file format can be imported and translated to R objects with the haven package; however, we needed to re-design haven’s labelled_spss class to maintain far more metadata, which, in turn, a modification of the labelled class. The haven package was designed and tested with data stored in individual SPSS files.
The author of labelled, Joseph Larmarange describes two main approaches to work with labelled data, such as SPSS’s method to store categorical data in the Introduction to labelled.

Our approach is a further extension of Approach B. Survey harmonization in our case always means the joining data from several SPSS files, which requires a consistent coding among several data sources. This means that data cleaning and recoding must take place before conversion to factors, character or numeric vectors. This is particularly important with factor data (and their simple character conversions) and numeric data that occasionally contains labels, for example, to describe the reason why certain data is missing. Our tutorial vignette labelled_spss_survey gives you more information about this.
In the next series of tutorials, we will deal with an array of problems. These are not for the faint heart – you need to have a solid intermediate level of R to follow.
Tidy, joined survey data
- The original files identifiers may not be unique, we have to create new, truly unique identifiers. Weighting may not be straightforward.
- Neither the number of observations or the number of variables (which represents the survey questions and their translation to coded data) is the same. Certain data may be only present in one survey and not the other. This means that you will likely to run loops on lists and not data.frames, but eventually you must carefully join them.
Class conversion
- Similar questions may be imported from a non-native R format, in our
case, from an SPSS files, in an inconsistent manner. SPSS’s variable
formats cannot be translated unambiguously to R classes.
retroharmonizeintroduced a new S3 class system that handles this problem, but eventually you will have to choose if you want to see a numeric or character coding of each categorical variable. - The harmonized surveys, with harmonized variable names and harmonized value labels, must be brought to consistent R representations (most statistical functions will only work on numeric, factor or character data) and carefully joined into a single data table for analysis.
Harmonization of variables and variable labels
- Same variables may come with dissimilar variable names and variable labels. It may be a challenge to match age with age. We need to harmonize the names of variables.
- The harmonized variables may have different labeling. One may call
refused answers as
declinedand the otherrefusal. On a simple choice, climate change may be ‘Climate change’ orProblem: Climate change. Binary choices may have survey-specific coding conventions. Value labels must be harmonized. There are good tools to do this in a single file - but we have to work with several of them.
Missing value harmonization
- There are likely to be various types of
missing values. Working with missing values is probably where most human judgment is needed. Why are some answers missing: was the question not asked in some questionnaires? Is there a coding error? Did the respondent refuse the question, or sad that she did not have an answer?retroharmonizehas a special labeled vector type that retains this information from the raw data, if it is present, but you must make the judgment yourself – in R, eventually you will either create a missing category, or useNA_character_orNA_real_.
That’s a lot to put on your plate.
It is unlikely that you will be able to work with completely unfamiliar survey programs if you do not have a strong intermediate level of R. Our package comes with tutorials for Eurobarometer, Afrobarometer and our development version already covers Arab Barometer, highlighting some peculiar issues with these survey programs, that we hope to give a head start for less experienced R users.