There are Numerous Advantages of Switching from a National Level of the Analysis to a Sub National Level
Maping Regional Data, Maping Metadata Problems

The new version of our rOpenGov R package regions was released today on CRAN. This package is one of the engines of our experimental open data-as-service Green Deal Data Observatory , Economy Data Observatory , Digital Music Observatory prototypes, which aim to place open data packages into open-source applications.
In international comparison the use of nationally aggregated indicators often have many disadvantages: they inhibit very different levels of homogeneity, and data is often very limited in number of observations for a cross-sectional analysis. When comparing European countries, a few missing cases can limit the cross-section of countries to around 20 cases which disallows the use of many analytical methods. Working with sub-national statistics has many advantages: the similarity of the aggregation level and high number of observations can allow more precise control of model parameters and errors, and the number of observations grows from 20 to 200-300.
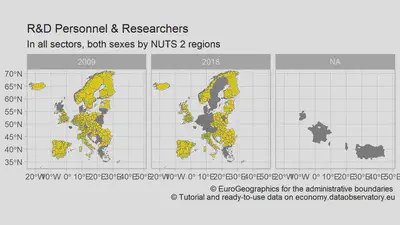
Yet the change from national to sub-national level comes with a huge data processing price. While national boundaries are relatively stable, with only a handful of changes in each recent decade. The change of national boundaries requires a more-or-less global consensus. But states are free to change their internal administrative boundaries, and they do it with large frequency. This means that the names, identification codes and boundary definitions of sub-national regions change very frequently. Joining data from different sources and different years can be very difficult.
 helps the data processing, validation and imputation of sub-national, regional datasets and their coding.](/media/img/blogposts_2021/recoded_indicator_with_map_hubda8124fbfd6305eacfd3d4f0fcd06cc_71873_65df57cf4311bb2623535a1a5be044c0.webp)
There are numerous advantages of switching from a national level of the analysis to a sub-national level comes with a huge price in data processing, validation and imputation, and the regions package aims to help this process.
You can review the problem, and the code that created the two map comparisons, in the Maping Regional Data, Maping Metadata Problems vignette article of the package. A more detailed problem description can be found in Working With Regional, Sub-National Statistical Products.
This package is an offspring of the eurostat package on rOpenGov. It started as a tool to validate and re-code regional Eurostat statistics, but it aims to be a general solution for all sub-national statistics. It will be developed parallel with other rOpenGov packages.
Get the Package
You can install the development version from GitHub with:
devtools::install_github("rOpenGov/regions")
or the released version from CRAN:
install.packages("regions")
You can review the complete package documentation on regions.dataobservaotry.eu. If you find any problems with the code, please raise an issue on Github. Pull requests are welcome if you agree with the Contributor Code of Conduct
If you use regions in your work, please cite the
package as:
Daniel Antal, Kasia Kulma, Istvan Zsoldos, & Leo Lahti. (2021, June 16). regions (Version 0.1.7). CRAN. http://doi.org/10.5281/zenodo.4965909
Join us
Join our open collaboration Economy Data Observatory team as a data curator, developer or business developer. More interested in environmental impact analysis? Try our Green Deal Data Observatory team! Or your interest lies more in data governance, trustworthy AI and other digital market problems? Check out our Digital Music Observatory team!
