Including Indicators from Arab Barometer in Our Observatory
New version of retroharmonize released on CRAN
 Climate Awareness in the Arab World. Get this plot from figshare.
Climate Awareness in the Arab World. Get this plot from figshare.A new version of the retroharmonize R package – which is working with retrospective, ex post harmonization of survey data – was released yesterday after peer-review on CRAN. It allows us to compare opinion polling data from the Arab Barometer with the Eurobarometer and Afrorbarometer. This is the first version that is released in the rOpenGov community, a community of R package developers on open government data analytics and related topics.
Surveys are the most important data sources in social and economic statistics – they ask people about their lives, their attitudes and self-reported actions, or record data from companies and NGOs. Survey harmonization makes survey data comparable across time and countries. It is very important, because often we do not know without comparison if an indicator value is low or high. If 40% of the people think that climate change is a very serious problem, it does not really tell us much without knowing what percentage of the people answered this question similarly a year ago, or in other parts of the world.
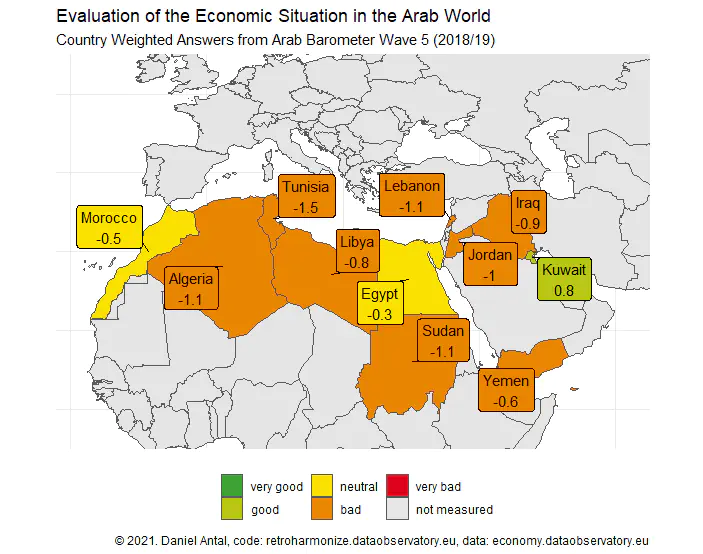
With the help of Ahmed Shabani and Yousef Ibrahim, we created a third case study after the Eurobarometer, and Afrobarometer, about working with the Arab Barometer harmonized survey data files.
Ex ante survey harmonization means that researchers design questionnaires that are asking the same questions with the same survey methodology in repeated, distinct times (waves), or across different countries with carefully harmonized question translations. Ex post harmonizations means that the resulting data has the same variable names, same variable coding, and can be joined into a tidy data frame for joint statistical analysis. While seemingly a simple task, it involves plenty of metadata adjustments, because established survey programs like Eurobarometer, Afrobarometer or Arab Barometer have several decades of history, and several decades of coding practices and file formatting legacy.
- Variable harmonization means that if the same question is called
in one microdata source
Q108and the othereval-parl-electionsthen we make sure that they get a harmonize and machine readable name without spaces and special characters. - Variable label harmonization means that the same questionnaire items get the same numeric coding and same categorical labels.
- Missing case harmonization means that various forms of missingness are treated the same way.
, and the plot in `jpg` or `png` from [figshare](https://figshare.com/articles/figure/arab_barometer_5_econ_eval_by_country_png/14865498).](/img/blogposts_2021/arab_barometer_5_evon_eval_by_country.png)
jpg or png from figshare.In our new Arab Barometer case
study,
the evaulation of parliamentary elections has the following labels. We
code them consistently 1: free_and_fair, 2: some_minor_problems,
3: some_major_problems and 4: not_free.
| “0. missing” | “1. they were completely free and fair” |
| “2. they were free and fair, with some minor problems” | “3. they were free and fair, with some major problems” |
| “4. they were not free and fair” | “8. i don’t know” |
| “9. declined to answer” | “Missing” |
| “They were completely free and fair” | “They were free and fair, with some minor breaches” |
| “They were free and fair, with some major breaches” | “They were not free and fair” |
| “Don’t know” | “Refuse” |
| “Completely free and fair” | “Free and fair, but with minor problems” |
| “Free and fair, with major problems” | “Not free or fair” |
| “Don’t know (Do not read)” | “Decline to answer (Do not read)” |
Of course, this harmonization is essential to get clean results like this:
 open repository.](/media/img/blogposts_2021/arabb-comparison-country-chart_hu876e56138097bf35e9ab80c0a7351314_159521_30b9d9bccbe8f347c912dbe10ef5159c.webp)
In our case study, we had three forms of missingness: the respondent did not know the answer, the respondent did not want to answer, and at last, in some cases the respondent was not asked, because the country held no parliamentary elections. While in numerical processing, all these answers must be left out from calculating averages, for example, in a more detailed, categorical analysis they represent very different cases. A high level of refusal to answer may be an indicator of surpressing democratic opinion forming in itself.
Survey harmonization with many countries entails tens of thousands of small data management task, which, unless automatically documented, logged, and created with a reproducible code, is a helplessly error-prone process. We believe that our open-source software will bring many new statistical information to the light, which, while legally open, was never processed due to the large investment needed.
We also started building experimental APIs data is running retroharmonize regularly. We will place cultural access and participation data in the Digital Music Observatory, climate awareness, policy support and self-reported mitigation strategies into the Green Deal Data Observatory, and economy and well-being data into our Economy Data Observatory.
Further plans
Retrospective survey harmonization is a far more complex task than this blogpost suggest. Retrospective survey harmonization is a far more complex task than this blogpost suggest, because established survey programs have gathered decades of legacy data in legacy coding schemes and legacy file formats. Putting the data right, and especially putting the invaluable descriptive and administrative (processing) metadata right is a huge undertaking. We are releasing example codes, datasets and charts for researchers to comapre our harmonized results with theirs, and improve our software. We are releasing example codes, datasets and charts for researchers to comapre our harmonized results with theirs, and improve our software.
Use our software
The retroharmonize R package can be freely used, modified and
distributed under the GPL-3 license. For the main developer and
contributors, see the
package homepage. If you
use it for your work, please kindly cite it as:
Daniel Antal (2021). retroharmonize: Ex Post Survey Data Harmonization. R package version 0.1.17. https://doi.org/10.5281/zenodo.5034752
Download the BibLaTeX entry.
Tutorial to work with the Arab Barometer survey data
Daniel Antal, & Ahmed Shaibani. (2021, June 26). Case Study: Working With Arab Barometer Surveys for the retroharmonize R package (Version 0.1.6). Zenodo. https://doi.org/10.5281/zenodo.5034759
For the replication data to report potential issues and improvement suggestions with the code:
Daniel Antal, & Ahmed Shaibani. (2021). Replication Data for the retroharmonize R Package Case Study: Working With Arab Barometer Surveys (Version 0.1.6) [Data set]. Zenodo. https://doi.org/10.5281/zenodo.5034741
Experimental API
We are also experimenting with the automated placement of authoritative
and citeable figures and datasets in open repositories. For the climate
awareness dataset get the country averages and aggregates from
Zenodo, and the plot in jpg
or png from figshare.
Our plan is to release open data in a modern API with rich descriptive
metadata meeting the Dublin Core and DataCite standards, and further
administrative metadata for correct coding, joining and further
manipulating or data, or for easy import into your database.
Join our open source effort
Want to help us improve our open data service? Include Lationbarómetro and the Caucasus Barometer in our offering? Join the rOpenGov community of R package developers, an our open collaboration to create the automated data observatories. We are not only looking for developers, but data curators and service design associates, too.