Open Policy Analysis
Improving the quality and transparency of policy design
Our ambition is to truly maximize transparency, (re)usability, scientific, policy, and business impact while embracing the best practices laid out in the the recommendations of the Reproducibility of scientific results scoping report, and the Progress on Open Science: Towards a Shared Research Knowledge System policy documents of the European Commission’s DG Research & Innovation, as well as the best practices outlined in the evidence-based Knowledge4Policy K4P platform of the European Commission.
For the first time in Europe, we will apply and contextualize the Open Policy Analysis Guidelines (OPA Guidelines) in our OpenMuse project.
The Open Policy Analysis Guidelines grew out of several initiatives in research transparency with the aim of maximizing benefits in the context of the Foundations for Evidence-based Policy Making Act of 2018 initiative in the United States. We want to ensure that by relying not only on the best European practices, but considering trans-Atlantic experiences, we will make the most out of the opportunities offered by the European Open Data Directive of 2019. This will not only mean rendering a dramatically increased data availability for our partners, as well as increased quality assurance and transparency in our work, but also immediate data access.
Our new software will continue to run in the cloud, depositing all of our findings—Findable, Accessible, Interoperable and Reuseable digital assets, including our well-designed and user-tested indicators in 41 data gap fields—into our Digital Music Observatory, which already hosts a modern REST API similar to the Eurostat Rest API.
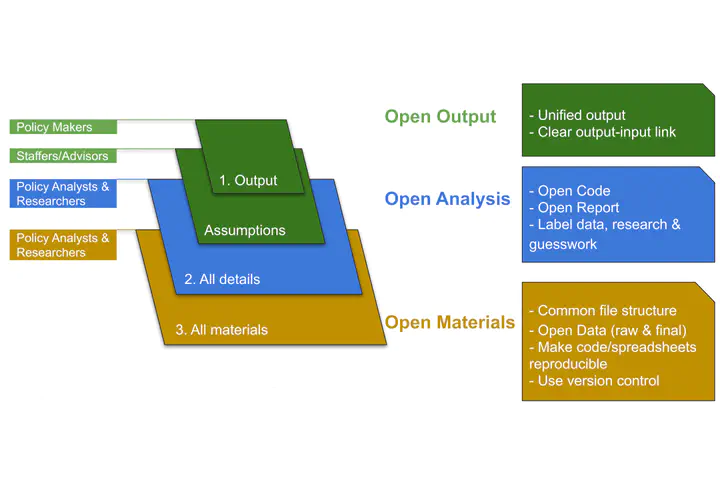
| Layer | Goal | Target | Example |
|---|---|---|---|
| Open Output | Ensure unified output | We comply with the level 3 requirements and we will create a showcase how to do this best following EU open science recommendations. | See our example. |
| Open Output | Establish a clear link between input and output | We will produce more than 100 outputs, some only as indicators, and others in form of policy analysis, we will comply with level 1,2,3 as necessary. | Our affiliated music industry partners will create cases studies with interactive tools (level 3). See our Slovak case study which came with a Shiny App that analyzed music recommendations. |
| Open Analysis | Provide clear accounts of all methodological procedures in a way that is easily interpreted by an informed reader. | We accomplish level 3 with placing the code in clearly documented. into a dynamic document, or open notebook | See for example our blogpost on automatic forecasting for the music industry. |
| Open Analysis | Share raw (or analytic) data and materials in a way that the analysis is reproducible with minimal effort. | We will accomplish level 3 through trusted repositories following EU recommendations. We will use the Zenodo repository developed by CERN and the EU’s OpenAIRE project. | See our solution on Zenodo. |
| Open Analysis | Share an open report that includes clear accounts of all methodological procedures, data, and assumptions. | We would like to go beyond the level 3 requirements of the OPA with using standardized documentation languages, such as SDMX statistical metadata and its standardized codebooks, and comply with both Dublin Core and DataCite extended, recommended standarized reporing. | See our example An Empirical Analysis of Music Streaming Revenues and Their Distribution created for the UK Intellectual Property Office’s evidence-based policy effort in music streaming. |
| Open Materials | Standardize the file structure so that materials are organized in a way that is accessible to an informed reader. | We comply with the level 3 requirements. Our versioned controled output is on Github. | See an example on Github. |
| Open Materials | Label and document each input, including data, research, and guesswork. | We will go beyond level 3 requirements, because we want to make sure that our labelling and documentation is interopreable, and we apply various metadata standards for this purpose. | See our example explaining how we document our datasets in our API. |
| Open Materials | Ensure that code/spreadsheets are reproducible. | All our spreadsheets are machine generated for the convenience of the user who uses spreadsheet applications, but everything can be run with a click, which accomplishes level 3, and maintains the convenience of level 1-2 for the user. We go further with creating authoritative copies of each dataset and visualization with DOIs. We also produce an API which gives programatic or single table access to both the data and standardized codebooks. | See our API. All our datasets are described in detail on Zenodo and Figshare, too. |
| Open Materials | Use a version control strategy. | We use Git version control, and we employ various repositories and project documentation tools on Github. These are linked with the Zenodo EU open repository and our data API. | See our example intergration. |
Competition Data Observatory
A forming new open collaboration for computational antitrust
A fully automated, open source, open data observatory that produces new indicators from open data sources and experimental big data sources, with authoritative copies and a modern API.