Create Data Frames that are Easier to Exchange and Reuse
New release of the dataset R package
Reprex released the 0.2.6 version of its [dataset] R package to make data frames easier to exchange and reuse. The new release considers feedback and experience since the first official release and the peer review process on rOpenSci. What is under the hood of the new release?
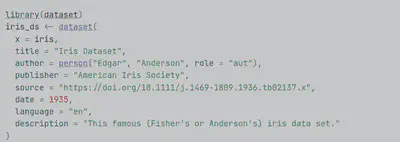
Seemingly not much, and we would like to keep it that way! We aim to provide much better metadata handling without interfering with what their code does with the tabular data itself in various data processing or statistical applications. End-users should recognise little from the new functionality; the dataset package is intended to provide R developers with a non-intrusive, modern accessory for their tabular data carrier object, the good old data.frame, or its more modern tibble, tsibble (for time series) and data.table versions.
For every day R users, some more usability testing and rich tutorials are needed, but the benefits are already clear. Our main goal is to provide far greater interoperability and reusability of datasets created in the R environments; therefore, we aim to attach more standardised metadata about the provenance (history), creators, storage, and semantics (meaning) of the data. R objects themselves do not hold the information that is required to be placed in an open science repository like Zenodo or to describe the meaning of variables so that an analyst (or a colleague) can immediately understand how to work with the data a year from now.
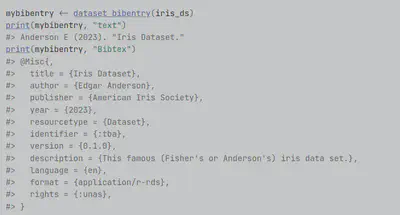
We provide a simple, functional interface to add Dublin Core or DataCite metadata for the R objects before they are serialised (or written into a CSV, Excel, STATA, or SPSS file.) We ensure that the native R .rds format contains the important metadata for findability, interoperability, accessibility, and reuse, and we build exporting (serialisation) tools to include this in any file you create. It seems like a very natural requirement, yet we did not find any R package that could do this without detaching the metadata from the data.
The other functionality is the ability to describe your dataset with semantics that computers and other users can understand. Imagine that you have variables like “GEO” for the countries and “SEX” for male and female dimensions of “WAGE”. We attach the Statistical Data and Metadata eXchange human- and machine-readable definitions of these variables to your dataset. This way, you gain a lot of new functionality. Did you label your variables in French, and do you need them in German? Standards code list translations are a few clicks away. Would you like to find information about the female/male wage gap in the industry you research? The standard codes for SEX and WAGE will help you to search the data catalogues of almost every statistical authority and public data source with 1-2 clicks.
And these are only the most obvious advantages for an everyday R user. For R developers, the functionality of dataset can greatly increase the usability and interoperability of your packages. We aim to be very light with dependencies and fully support tibble in the tidyverse and its time-series version tsibble, the popular and indexable data.table used by many quantitative packages, and rdflib for linked data serialisations.
Reprex
Big data for all
Reprex is a Netherlands-based AI company that builds data-sharing spaces and knowledge bases to deliver trustworthy, explainable, and human-controlled AI.