Big Data For All
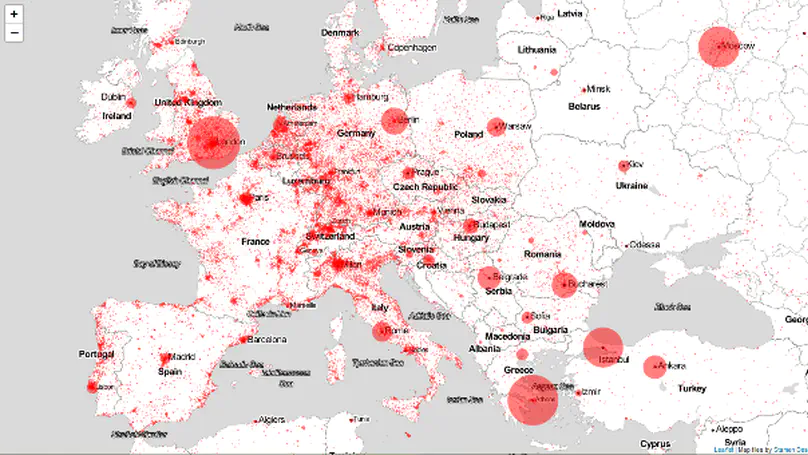
We make messy, fragmented, and biased data reliable and transparent. By merging public and private sources into secure data-sharing spaces, we give AI the trustworthy foundations it needs. The result: reliable analytics and scalable AI solutions that power smarter decisions in operations, planning, research, and markets.

Data Sharing Spaces
Our Data Sharing Spaces implement the European Interoperability Framework (EIF) to connect diverse datasets on an as-needed, as-permitted basis. They enable organisations to share trustworthy data securely while respecting legal and technical differences.
*


Systems
*


Regenerative, AI-supported data spaces that not only store clean data but also preserve the know-how to repair, modernise, and extend the life of legacy systems.
Connected financial and sustainability reporting
Listen Local is a trustworthy, ethical AI-powered system that aims to help great artists in small organizations and small countries using big data.
Accomplishments
TextileBase
TextileBase links museum, archive, and research records on garments into a multilingual knowledge graph to support dress history, cultural heritage, and sustainable fashion.
FUDSS
We built the Finno-Ugric Data Sharing Space as a federated platform that solves some of the hardest data challenges — linking scattered, multilingual, public and private collections while respecting local knowledge and legal frameworks. By stress-testing our methods in this complex cultural setting, we developed tools directly applicable to equally difficult business data problems across borders and industries.
Smart Policy Documents Monitor National Policy
Reprex’s Smart Policy Documents technology will be used to monitor the national cultural and creative industry policies of the Slovak Republic.
Finalist, Winner of Audience Prize
Our automated data observatory concept supported by a data-sharing space wins the audience prize.
OpenMuse
We initiated a Horizon Europe Research and Innovation action to launch our research automation tools from data collection to dissemination for scientific, business and policy partners.
Awarded project in the Green Recovery section of MusicAire.
Trustworthy AI Systems Hub
With our Digital Music Observatory and Listen Local we are partners in finding potential adverse outcomes of AI-driven, autonomous music recommendation systems on market competition.
Cultural Creative Sectors Industries Data Observatory
A first replication and extension attempt of our beachhead product, the Digital Music Observatory to serve the film, fashion, book, design, gaming industries.
Listen Local Slovakia Demo App & Feasibility Study
Slovak Arts Council & SOZA
Formalizing our automated data observatory product and our bridghead into the music industry
AI+Blockchain Product/Market Fit Validation
University X
Formalizing our automated data observatory product and our bridghead into the music industry
Central European Music Industry Report
A 12-country music data harmonization and reporting project with a a best-practice report.
Software
The new, very early stage tuRtle package helps the annotation of datasets created in the R statistical environment with the Resource Description Frameworks Turtle language for linking across the Internet.
The primary aim of dataset is create well-referenced, well-described, interoperable datasets that can be easily placed on global knowledge graphs using the W3C DataSet and RDF definition, or syncronized via APIs that follow the Statistical Data and Metadata eXchange standards.
Our minimum viable product will create CSRD sustainability reports.
statcodelists
Use the standardized codebooks of the Statistical Data and Metadata eXchange for international, language-independent, machine-to-machine data exchanges.
Malta and Germany are hard to compare. Compare provinces with provinces, regions with regions. Documentation & download
Never start a questionnaire from scratch. Recycle questions from question banks, answer from open data repositories, and let your respondents add theirs. Documentation & download
Tax, employment, green house gas multipliers, induced effects, policy scenarios. Documentation & download